- support@shidai5.com
- 0536-8066881
SEO��(y��u)��
�H���W(w��ng)վ��(y��u)��֮��������ץȡ����
���������ץȡ��������������A(ch��)�Ĺ���������m(x��)��һ�й�����䁉|��ץȡ���٣�ץȡ̫���؏�(f��)��Ϣ��ץȡ������ֱ��Ӱ��Ñ���ʹ���w�(y��n)���Bץȡ������������Ҳ����Մ�������Ϣ��ȡ�������ˡ���ˣ���������?zh��n)�һֱ��������Լ���ץȡ�����?/span>
һ�����ץȡ���̡�
��������ͨ�^�Լ�ԭ�е������б������M(j��n)��W(w��ng)վ����ץȡ�W(w��ng)퓣���ͨ�^����朽ӣ����M(j��n)����һ�ӾW(w��ng)퓣��Ķ�����������������б���URL�б���
�������ץȡ�ķ�ʽ
1�� �V�ȃ�(y��u)��
�V�ȃ�(y��u)�ȣ���ָ���W(w��ng)վ������Ŀץȡ֮��Ȼ����ץȡ����Ŀ������ә�Ŀ���V�ȃ�(y��u)��Ҫע�������c(di��n)��
(1)��Ҫ�W(w��ng)��x��վ�c(di��n)��һ����^��
(2)���ȃ�(y��u)��Ҏ(gu��)�t�����ڶ���(g��)���x������ȡ����ץվ��(n��i)��ץվ�⣬���]�ԏ�(qi��ng)
(3)�f�S�W(w��ng)����Ȳ����������е���
2����ȃ�(y��u)��
�c�V�ȃ�(y��u)�������෴���@�N���ȕ�(hu��)�x��ij��(g��)��֧���^�����뵽�����������r�²ſ��]������֧�IJ��ԡ�ͨ�^�@�N��ʽ��ץȡ�����^�[�ε���棬�Ķ���(sh��)�F(xi��n)�����Ñ��ęz��Ҫ��
3�W(w��ng)����L
�������ĸ��µĆ��}��������Ҫ�����L��
4���؏�(f��)ץȡ
�������治��(hu��)ץȡ��Ϣ��һ�ӵăɂ�(g��)�W(w��ng)퓡�����(hu��)�oԭ��(chu��ng)�ľW(w��ng)����Ը��ߙ�(qu��n)�ء�����Д�ԭ��(chu��ng)�����������(hu��)����(j��)�ĕr(sh��)�g���W(w��ng)վ��(qu��n)�ص����ؾC�Ͽ��]��
-
 �����Ƽ���(chu��ng)��δ����--�H��������Ӗ(x��n)�ИI(y��)������(hu��)���_����(li��n)�W(w��ng)+�����ИI(y��)ȫ�r(sh��)����
2015-06-15
�����Ƽ���(chu��ng)��δ����--�H��������Ӗ(x��n)�ИI(y��)������(hu��)���_����(li��n)�W(w��ng)+�����ИI(y��)ȫ�r(sh��)����
2015-06-15
-
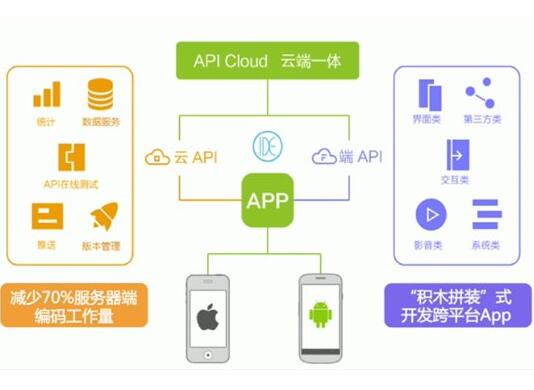 HTML5���ˣ�5��(g��)���õĻ��ʽApp�_�l(f��)���ߣ�
2015-06-15
HTML5���ˣ�5��(g��)���õĻ��ʽApp�_�l(f��)���ߣ�
2015-06-15
-
 Web�O(sh��)Ӌ(j��)���������e(cu��)�^��5��Material�O(sh��)Ӌ(j��)�YԴ��
2015-06-15
Web�O(sh��)Ӌ(j��)���������e(cu��)�^��5��Material�O(sh��)Ӌ(j��)�YԴ��
2015-06-15
-
 ��K�P�c(di��n)��2015�����T��ʮ������!
2015-06-15
��K�P�c(di��n)��2015�����T��ʮ������!
2015-06-15
-
 ��վ�L���Ã�(y��u)���Ď��c(di��n)�������ܷ�������؛���u��
2015-06-15
��վ�L���Ã�(y��u)���Ď��c(di��n)�������ܷ�������؛���u��
2015-06-15